|
I am a third-year computer science PhD candidate at Harvard University, advised by Professor Demba Ba. I am supported by the Kempner Institute Graduate Fellowship. Visual Representation Learning Interpretability My work investigates how large-scale vision models transform high-dimensional visual inputs into structured semantic representations. I am interested in training vision foundation models and understanding them through mechanistic interpretability approaches that reveal the computational principles underlying machine vision. My goal is to leverage these insights to engineer architectural inductive biases that enhance efficiency, robustness, and generalization while remaining compatible with large-scale training. Recently, I have been exploring dynamical interpretability—analyzing how representations evolve as trajectories through activation space—to uncover convergence dynamics, token-specific behaviors, and low-dimensional geometric structure that governs how vision models process information. Previously, I worked at the AI Institute in Dynamic Systems with Nathan Kutz and Ryan Raut. I earned my B.S. in computer science from the Allen School at the University of Washington, where I worked with Rajesh Rao and William Noble. Email / CV / Google Scholar / Twitter / LinkedIn |

|
|
* denotes equal contribution |

|
Mozes Jacobs*, Thomas Fel*, Richard Hakim*, Alessandra Brondetta, Demba Ba, T. Andy Keller Accepted to ICLR, 2026 We introduce the Block-Recurrent Hypothesis (BRH), arguing that trained ViTs admit a block-recurrent depth structure. To validate this, we train recurrent surrogates called Raptor. We demonstrate that a Raptor model can recover 96% of DINOv2 ImageNet-1k linear probe accuracy in only 2 blocks while maintaining equivalent runtime. We leverage our hypothesis to perform dynamical interpretability, revealing directional convergence into class-dependent basins, token-specific trajectory dynamics, and low-rank attractor structure in late layers. |
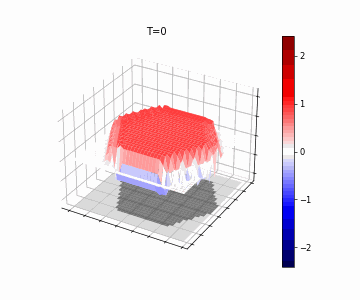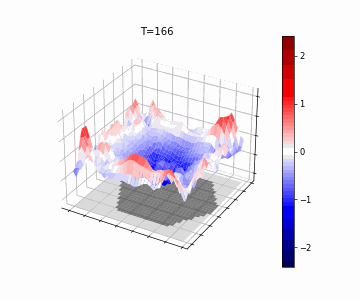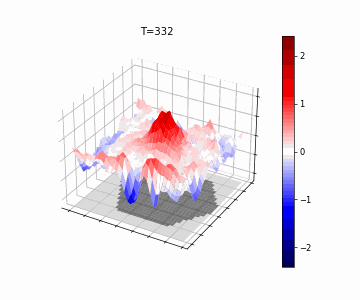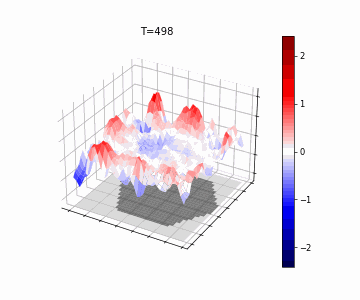
|
Mozes Jacobs, Robert C. Budzinski, Lyle Muller, Demba Ba, T. Andy Keller CCN (Oral), 2025 blog / talk We investigate how traveling waves of neural activity enable spatial information integration in convolutional recurrent networks. Our models learn to generate traveling waves in response to visual stimuli, effectively expanding receptive fields of locally connected neurons. This mechanism significantly outperforms local feed-forward networks on semantic segmentation tasks requiring global spatial context, achieving comparable performance to non-local U-Nets while using significantly fewer parameters. |
|
|
|
Mozes Jacobs, Robert C. Budzinski, Lyle Muller, Demba Ba, T. Andy Keller ICLR 2025 Re-Align Workshop |
|
|
Mozes Jacobs, Bingni W. Brunton, Steven L. Brunton, J. Nathan Kutz, Ryan V. Raut arXiv, 2023 |
|
|
Mozes Jacobs, Linxing Preston Jiang, Rajesh N.P. Rao Undergraduate senior thesis, 2022 |
|
Website template from Jon Barron |